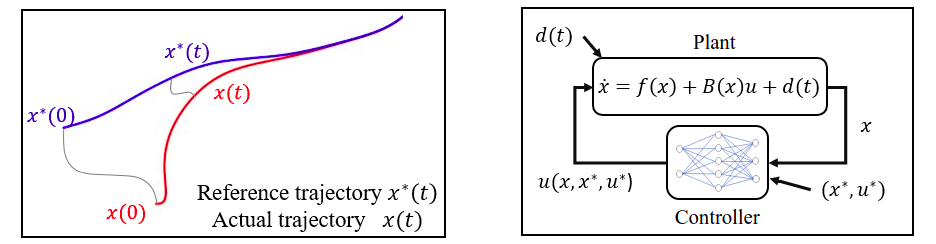
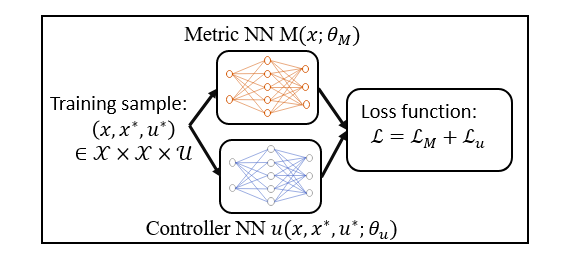
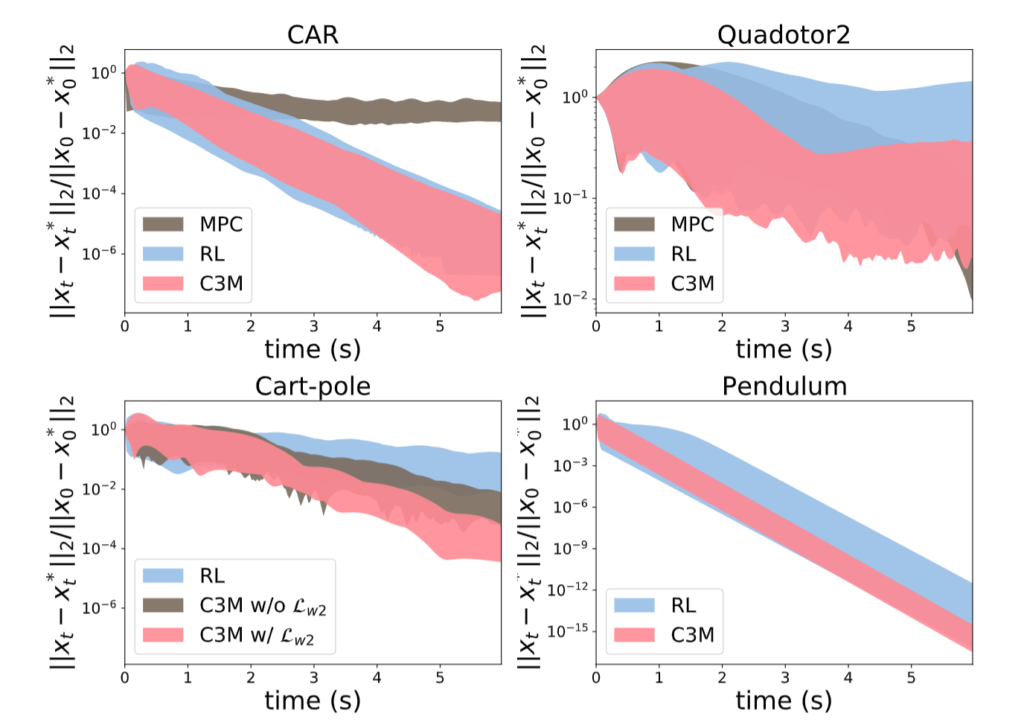
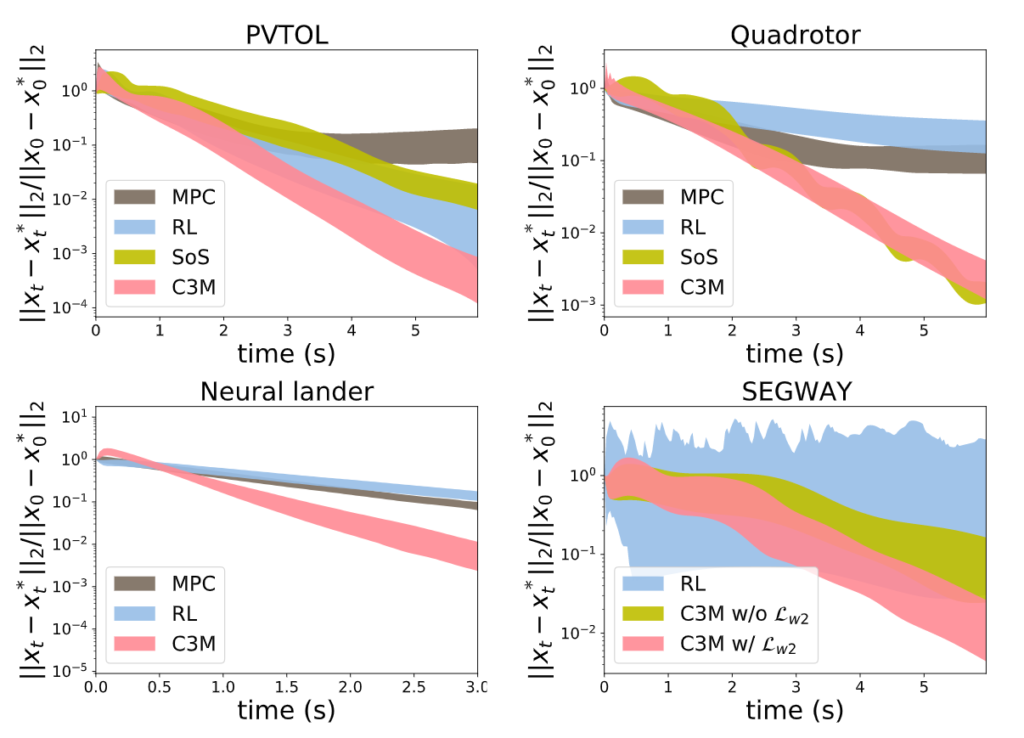
This blog is a summary of the first part of the course ECE543@UIUC. More materials can be found here.
Problem setup
In this blog, we will focus on the binary classification problem, where the input is $X \in \mathbb{R}^D$, and the label is $Y \in \{0, 1\}$. A set of i.i.d. training samples $S = \{(X_1, Y_1), \dots, (X_n, Y_n)\}$ are drawn from a joint distribution $P$ defined over $\mathbb{R}^D \times \{0,1\}$. Sometimes, we may also denote $Z = (X, Y)$ and $Z_i = (X_i, Y_i)$. A hypothesis is a mapping $h: \mathbb{R}^D \mapsto \{0, 1\}$. Moreover, $\mathcal{H}$ denotes the hypotheses class, which consists of all the possible hypotheses that our model (e.g. a neural network) can represent. The learning algorithm is denoted by $\mathcal{A}$, which maps a dataset $S$ to a hypothesis $h_S \in \mathcal{H}$.
Given a hypothesis $h$, we define its true risk as $$L_P(h) = \mathbb{E}_{(X, Y) \sim P}~\mathbb{I}_{h(X) \neq Y},$$ and the empirical risk on $S$ as $$L_S(h) = \frac{1}{n}\sum_{i=1}^{n} \mathbb{I}_{h(X_i) \neq Y_i}.$$
PAC-learnability
After applying the learning algorithm $\mathcal{A}$ to the dataset $S$, we get a hypothesis $h_S$ which depends on $S$ and minimizes the empirical risk $L_S(h)$. We care about the difference between the true risk of $h_S$ and that of $h^*$. Here, $h^*$ is the best hypothesis in the sense of minimizing the true risk, i.e. $h^* = \text{arg} \min\limits_{h \in \mathcal{H}} L_P(h)$. In other words, we want to get some guarantees on $L_P(h_S)-L_P(h^*)$.
However, $L_P(h_S)-L_P(h^*)$ is a random variable since $h_S$ depends on $S$ which is random. Therefore, it is not reasonable to look for a uniform upper bound on $L_P(h_S)-L_P(h^*)$. In the PAC (Probably Approximately Correct) learning framework, instead of a uniform upper bound, we care about guarantees of the form $$\Pr(L_P(h_S)-L_P(h^*) \geq \epsilon) \leq \delta.$$ Here, “Probably” is characterized by $\delta$, and “Approximately” is characterized by $\epsilon$. Next, we give the definition of PAC-learnability of a hypothesis class.
Definition 1 (PAC-learnability): A hypothesis class $\mathcal{H}$ is PAC-learnable if there exists an algorithm $\mathcal{A}$ such that for all data distribution $P_{X,Y}$ and all $\epsilon,\delta \in \mathbb{R}^+$, $\exists n=n(\epsilon,\delta)$ such that given any training set $S$ which contains at least $n$ samples, $h_S=\mathcal{A}(S)$ satisfies $$\Pr(L_P(h_S)-L_P(h^*) \geq \epsilon) \leq \delta.$$
Theorem 1 (No free lunch): This theorem shows that we need some restrictions on the hypothesis class. We cannot learn an arbitrary set of hypotheses: there is no free lunch. Please see these lecture notes 1 and 2 for details.
A trick
Using a small trick, $L_P(h_S) – L_P(h^*)$ can be bounded as follows. By doing this, $h_S$ and $h^*$ are eliminated.
$$\begin{multline} L_P(h_S) – L_P(h^*) = [L_P(h_S) – L_S(h_S)] + [L_S(h^*) – L_P(h^*)] \\+ [L_S(h_S) – L_S(h^*)]_{(\text{this term}\leq 0)} \\\leq [L_P(h_S) – L_S(h_S)] + [L_S(h^*) – L_P(h^*)] \\\leq 2\sup\limits_{h \in \mathcal{H}} \left|L_P(h)-L_S(h)\right| = 2 \mathcal{V},\end{multline}$$ where $\sup\limits_{h \in \mathcal{H}} \left|L_P(h)-L_S(h)\right|$ is denoted by $\mathcal{V}$.
Thus, $$\Pr(L_P(h_S)-L_P(h^*) \geq \epsilon) \leq \Pr(\mathcal{V} \geq \frac{\epsilon}{2}).$$
Theorem 2: Finite hypothesis classes are PAC-learnable.
Proof: Since $|\mathcal{H}|<\infty$, we can first bound $\Pr\left(\left|L_S(h)-L_P(h)\right|\geq\frac{\epsilon}{2}\right)$ for each $h$ and then apply the union bound. For all $\epsilon > 0$ and all sets $S$ with $n$ samples, We have that $$\begin{align} &\Pr\left(L_P(h_S)-L_P(h^*) \geq \epsilon\right)\\ \leq &\Pr\left(\max\limits_{h \in \mathcal{H}} \left|L_S(h)-L_P(h)\right| \geq \frac{\epsilon}{2}\right)\\= &\Pr\left(\cup_{h \in \mathcal{H}} \left\{\left|L_S(h)-L_P(h) \right| \geq \frac{\epsilon}{2}\right\}\right)\\\leq &\sum_{h\in\mathcal{H}}\Pr\left(\left|L_S(h) – L_P(h) \right|\geq\frac{\epsilon}{2}\right) \\= &\sum_{h\in\mathcal{H}}\Pr\left(\left|\frac{1}{n}\sum_{i=1}^{n}\mathbb{I}_{h(x_i)\neq y_i} – L_P(h) \right|\geq\frac{\epsilon}{2}\right) \\\leq &\sum_{h\in\mathcal{H}} \exp\left(-\frac{2n\epsilon^2}{4}\right) = |\mathcal{H}|\exp\left(-\frac{n\epsilon^2}{2}\right) = \delta, \end{align}$$ where in the last step we use the Hoeffding’s inequality. Thus, $n(\epsilon, \delta) = \frac{2}{\epsilon^2}\log(\frac{|\mathcal{H}|}{\delta})$.
Theorem 1 is not very useful since almost all hypothesis classes we care about contain infinite hypotheses.
McDiarmid’s inequality
In order to derive PAC bounds for infinite hypothesis classes, we need some more sophisticated concentration inequalities.
Theorem 3 (McDiarmid’s inequality): Let $X_1, \dots, X_n$ be i.i.d. random variables. Let $f$ be a function of $n$ variables. If $\forall x_i, x_i’$, $$|f(x_1,\dots,x_i,\dots,x_n) – f(x_1,\dots,x_i’,\dots,x_n)| \leq c_i,$$ then $\forall \epsilon>0$, $$\Pr(f(X_1,\dots,X_n)-\mathbb{E}\left[f(X_1,\dots,X_n)\right] \geq \epsilon) \leq \exp\left(\frac{-2\epsilon^2}{\sum_{i=1}^{n}c_i}\right).$$ Such a function $f$ is said to have bounded differences.
Proof: TODO.
It can be shown that $\mathcal{V}$ has bounded differences, and thus McDiarmid’s inequality can be applied. Next, we have to derive an upper bound for $\mathbb{E}\left[\mathcal{V}\right]$.
Rademacher complexity
Definition 2 (Rademacher complexity of a set): Let $A \subseteq \mathbb{R}^n$, the Rademacher complexity $R(A)$ of set $A$ is defined as follows. $$R(A) = \mathbb{E}_{\sigma}\left[\sup\limits_{a \in A} \left|\frac{1}{n}\sum_{i=1}^{n}\sigma_i a_i\right|\right],$$ where $\sigma_i$’s are i.i.d. random variables and $\forall i$, $\Pr(\sigma_i = 1) = \Pr(\sigma_i = -1) = 0.5$.
Intuitively, Rademacher complexity characterizes the diversity of a set. If for every direction vector $\sigma = [\sigma_1, \cdots, \sigma_n]$, we can always find an element $a \in A$ such that the inner product of $\sigma$ and $a$ is large, then $R(A)$ would be large.
Theorem 4: The expectation of $\mathcal{V}$ can be bounded as follows. $$\mathbb{E}_S\left[\mathcal{V}\right] \leq 2\mathbb{E}_S \left[R(\mathcal{F}(S))\right],$$ where $\mathcal{F}(S) = \left\{\left(\mathbb{I}_{h(x_1) \neq y_1}, \cdots, \mathbb{I}_{h(x_n) \neq y_n}\right), h \in \mathcal{H}\right\}.$
Proof: To simplify the notation, the loss term $\mathbb{I}_{h(x_i)\neq y_i}$ is denoted by $f(z_i)$. Moreover, the set of all $f$’s is denoted by $\mathcal{F}$. The training set $S = \{Z_i\}_{i=1}^{n}$ is the source of randomness. Thus, $$\begin{align} &\mathbb{E}_S\left[\mathcal{V}\right]\\ = &\mathbb{E}_S\left[\sup\limits_{f\in\mathcal{F}}\left|\frac{1}{n}\sum_{i=1}^{n}f(Z_i) – \mathbb{E}_Z\left[f(Z)\right]\right|\right]\\= &\mathbb{E}_S\left[\sup\limits_{f\in\mathcal{F}}\left|\frac{1}{n}\sum_{i=1}^{n}f(Z_i) – \frac{1}{n}\sum_{i=1}^{n}\mathbb{E}_{Z_i’}\left[f(Z_i’)\right]\right|\right],\end{align}$$ where we introduce a virtual validation set or a set of ghost samples $S’ := \{Z_i’\}_{i=1}^{n}$, which is independent of $S$. This is known as the symmertrization trick. Thus, $$\begin{align}&\mathbb{E}_S\left[\mathcal{V}\right]\\= &\mathbb{E}_S\left[\sup\limits_{f\in\mathcal{F}}\left|\mathbb{E}_{S’}\left[\frac{1}{n}\sum_{i=1}^{n}\left(f(Z_i) – f(Z_i’)\right)\right]\right|\right] \\ \underset{\text{Jensen’s}}{\leq} &\mathbb{E}_S\left[\sup\limits_{f\in\mathcal{F}}\mathbb{E}_{S’}\left[\left|\frac{1}{n}\sum_{i=1}^{n}\left(f(Z_i) – f(Z_i’)\right)\right|\right]\right]\\ \leq &\mathbb{E}_{S,S’}\left[\sup\limits_{f\in\mathcal{F}}\left|\frac{1}{n}\sum_{i=1}^{n}\left(f(Z_i) – f(Z_i’)\right)\right|\right].\end{align}$$ Since $\forall i$, $Z_i$ and $Z_i’$ are i.i.d., we have that the following three random variables have the same distribution, $$f(Z_i)-f(Z_i’)\stackrel{\mbox{d}}{=}f(Z_i’)-f(Z_i)\stackrel{\mbox{d}}{=}\sigma_i(f(Z_i)-f(Z_i’)).$$ Thus, $$\begin{align}&\mathbb{E}_S\left[\mathcal{V}\right]\\\leq&\mathbb{E}_{S,S’,\sigma}\left[\sup\limits_{f\in\mathcal{F}}\left|\frac{1}{n}\sum_{i=1}^{n}\sigma_i\left(f(Z_i) – f(Z_i’)\right)\right|\right]\\\leq&2\mathbb{E}_{S,\sigma}\left[\sup\limits_{f\in\mathcal{F}}\left|\frac{1}{n}\sum_{i=1}^{n}\sigma_if(Z_i)\right|\right]= 2\mathbb{E}_S\left[R(\mathcal{F}(S)\right].\end{align}$$
Some properties of Rademacher complexity
Rademacher calculus:
The following theorem is useful when dealing with the composition of a function and a set.
Theorem 5 (contraction principle): Let $A\subseteq \mathbb{R}^n$, $\phi: \mathbb{R}\mapsto\mathbb{R}$, $\phi(0) = 0$, and $\phi(\cdot)$ be $M$-Lipschitz continuous. Applying $\phi$ to the set $A$ leads to a new set $\phi \circ A = \left\{\left(\phi(a_1), \cdots, \phi(a_n)\right), a \in A\right\}$. Then, the Rademacher complexity of $\phi \circ A$ is bounded as follows. $$R\left(\phi \circ A\right) \leq 2MR(A).$$
VC-dimension
Theorem 6 (finite class lemma): Suppose $A = \{a^{(1)},\dots,a^{(N)}\}$ is a finite subset of $\mathbb{R}^n$ for $N>2$ and $||a^{(i)}|| \leq L,\,\forall i$, then the Radmacher complexity of $A$ is bounded as follows, $$R_n(A) \leq \frac{2L\sqrt{\log N}}{n}.$$
- finite class lemma
- definition of VC-dimension
- VC’s lemma
- relationship of Rademacher complexity and VC-dimension
Others
- surrogate loss function
- contraction principle
Some examples
Now, we consider the separators on $\mathbb{R}^d$. Given $\Gamma \subseteq \mathbb{R}^d$ and a data distribution $\mathcal{D}$ over $\Gamma$. A set of i.i.d. samples $S=\{Z_1,\dots,Z_n\}$ is sampled from $\Gamma$ conforming the distribution $\mathcal{D}$. Denoting $\mathcal{H}$ as the hypothesis class, the learning alorithm maps $S$ to a hypothesis $h_S \in \mathcal{H}$. Given a hypothesis $h$, define its true risk as $$L_P(h) = \mathbb{E}_{Z \sim \mathcal{D}}~\mathbb{I}_{h(Z) \neq 1},$$ and the empirical risk on $S$ as $$L_S(h) = \frac{1}{n}\sum_{i=1}^{n} \mathbb{I}_{h(Z_i) \neq 1}.$$
Then using the VC-theory, we can derive a PAC bound for this learning problem. Here, we assume this case is realizable, i.e. $L_P(h^*) = 0$.
$\begin{multline} L_P(h_S) – L_P(h^*) = [L_P(h_S) – L_S(h_S)] + [L_S(h^*) – L_P(h^*)] \\+ [L_S(h_S) – L_S(h^*)]_{\leq 0} \\\leq [L_P(h_S) – L_S(h_S)] + [L_S(h^*) – L_P(h^*)] \\\leq 2\sup\limits_{h \in \mathcal{H}} \left|L_P(h)-L_S(h)\right| = 2 \mathcal{V}\end{multline}$
Using the Radmacher average to bound $\mathbb{E}[\mathcal{V}]$, $$\mathbb{E}[\mathcal{V}] \leq 2\mathbb{E}[R(\mathcal{H}(Z^n))].$$
Then, we use the finite class lemma to bound the Radmacher average. Let $S_n(\mathcal{H}) = \sup\limits_{z^n}\left|\mathcal{H}(z^n)\right|$, then $$\mathbb{E}[R(\mathcal{H}(Z^n))] \leq \mathbb{E}\left[2\sqrt{\frac{\log S_n(\mathcal{H})}{n}}\right] = 2\sqrt{\frac{\log S_n(\mathcal{H})}{n}}.$$
Next, we use the VC-dimension and the Sauer–Shelah lemma to bound $S_n(\mathcal{H})$. The Sauer-Shelah lemma, $$S_n(\mathcal{H}) \leq \sum_{i=1}^{VC(\mathcal{H})} {n \choose i} \leq \left(\frac{ne}{d}\right)^{VC(\mathcal{H})}.$$ Thus, we finally have $$\mathbb{E} \left[L_P(h_S)\right] = \mathbb{E} \left[L_P(h_S) – L_P(h^*)\right] \leq 8\sqrt{\frac{VC(\mathcal{H}) (1 + \log \frac{n}{d})}{n}}.$$
Finally we use the McDiarmid’s inequality to derive a concentration property. We have $$\Pr\left(L_P(h_S) – \mathbb{E} \left[L_P(h_S)\right] \leq \frac{1}{2n}\sqrt{\log \frac{1}{\delta}}\right) \geq 1-\delta$$ which with the above results implies that with probability higher than $1-\delta$, $$L_P(h_S) \leq 8\sqrt{\frac{VC(\mathcal{H}) (1 + \log \frac{n}{d})}{n}} + \frac{1}{2n}\sqrt{\log \frac{1}{\delta}}.$$
With Dudley’s theorem, we can construct the so-called Dudley classes whose VC-dimension is known. Specifically, we can choose a basis of $n$ linearly independent functions to construct a $n$-dimensional Hilbert space of which the VC-dimension is $n$. For example, $\{1,x,\dots,x^n\}$ is a valid basis.